Java
为什么需要使用流
首先完成下列需求:
- 创建一个集合,存储多个字符串元素
- 把集合中所有以"张"开头的元素存储到一个新的集合
- 把"张"开头的集合中的长度为3的元素存储到一个新的集合
- 遍历上一步得到的集合
java
import java.util.ArrayList;
import java.util.Collections;
public class Demo1 {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "张三丰","张无忌","张翠山","王二麻子","张良","谢广坤");
ArrayList<String> list2 = new ArrayList<>();
for (String s : list1) {
if(s.startsWith("张")) {
list2.add(s);
}
}
System.out.println(list2);// [张三丰, 张无忌, 张翠山, 张良]
}
}而上述代码实现功能太过繁琐, 这时就可以体现流的作用
java
//只需要理解流的用处, 更加详细的介绍在后面
list1.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.startsWith("张") && s.length() == 3;
}
}).forEach(s -> System.out.println(s));// [张三丰, 张无忌, 张翠山, 张良]
//结合lambda表达式
list1.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(s -> System.out.println(s));提示
Stream流就像是一条流水线,数据从输入源(集合、数组)经过中间操作(过滤、映射等)最终操作输出到结果(集合、数组)- 中间操作 --
filter,map, ... - 最终操作 --
forEach,collect, ...
- 中间操作 --
介绍流
Stream流就像对食物进行消毒, 过滤, 最后进行包装. 而在编程中, 就是对数据进行一些操作, 最终返回我们需要的结果.
Stream流往往结合lambda表达式, 简化集合, 数组的操作
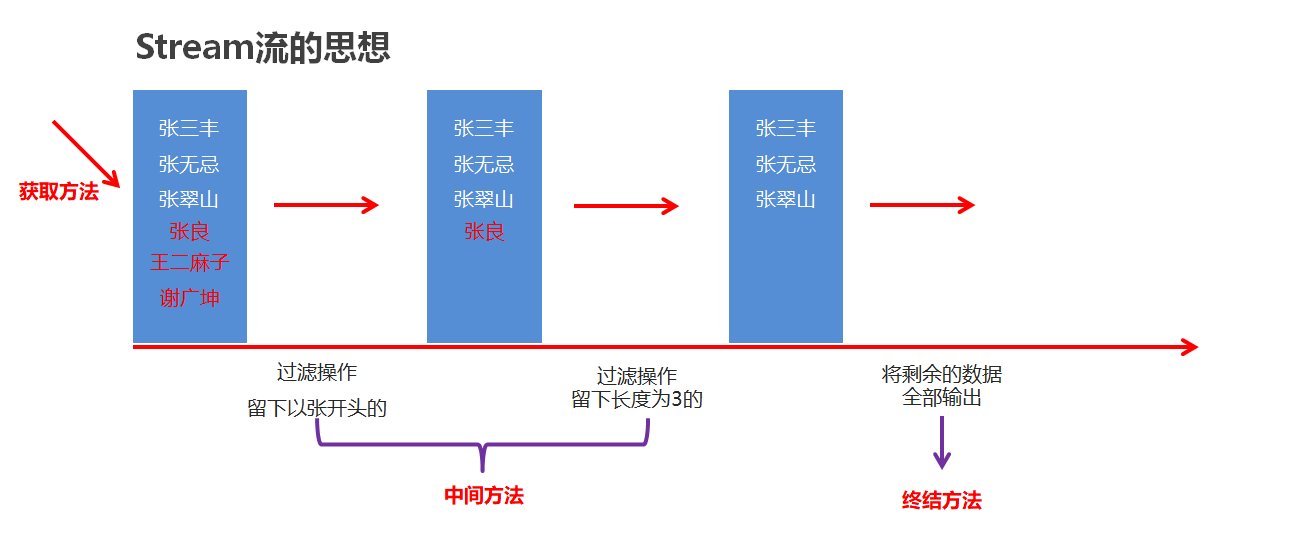
Stream流的三类方法
- 获取
Stream流- 创建一条流水线, 并把数据放到流水线上准备进行操作
- 中间方法
- 流水线上的操作
- 一次操作完毕之后, 还可以继续进行其他操作, 例如:
filter
- 终结方法
- 一个
Stream流只能有一个终结方法 - 是流水线上的最后一个操作, 例如:
forEach
- 一个
获取Stream流
| 获取方式 | 方法名 | 作用 |
|---|---|---|
| 单列集合 | default Stream<E> stream() | Collection中的默认方法, 实现此接口的类都可以直接使用此方法 |
| 双列集合 | 无 | 无法直接获取Stream流 |
| 数组 | static <T> Stream<T> stream(T[] array) | 通过Arrays.stream(Object[] a)获取一个默认的Stream流 |
| 一堆零散的数据 | static Stream<T> of(T... values) | Stream接口的静态方法 |
获取单列集合的流
java
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
public class Demo2 {
public static void main(String[] args) {
//单列集合使用流
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "张三丰", "张无忌", "张翠山", "王二麻子", "张良", "谢广坤");
//打印姓为张的信息
list1.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s));
HashSet<String> set = new HashSet<>();
Collections.addAll(set, "张三丰", "张无忌", "张翠山", "王二麻子", "张良", "谢广坤");
//HashSet无法保证顺序
set.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s));
}
}获取双列集合的流的方式
默认情况下, 双列集合无法获取流, 但是可以通过获得它的keySet或者EntrySet来获取流
java
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo3 {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("aaa", 111);
map.put("bbb", 222);
map.put("ccc", 333);
map.put("ddd", 444);
map.put("eee", 555);
//方式1
Set<String> keys = map.keySet();
keys.stream().forEach(key -> {
int value = map.get(key);
System.out.println(key + " = " + value);
});
//方式2
Set<Map.Entry<String, Integer>> entries = map.entrySet();
entries.stream().forEach(entry -> {
String key = entry.getKey();
int value = entry.getValue();
System.out.println(key + " = " + value);
});
}
}获取数组的流
java
import java.util.Arrays;
public class Demo4 {
public static void main(String[] args) {
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
//打印数组中的偶数
Arrays.stream(arr)
.filter(value -> value % 2 == 0)
.forEach(value -> System.out.println(value));
}
}获取零散数据的流
java
import java.util.stream.Stream;
public class Demo5 {
public static void main(String[] args) {
Stream.of(1, 2, 3, 4, 5, 6)
.filter(item -> item % 2 == 0)
.forEach(item -> System.out.println(item));
}
}Stream.of注意点
Stream.of方法形参是一个可变参数, 可以传递一堆零散的数据, 也可以传递数组, 但是数组必须是引用数据类型的, 如果传递基本数据类型, 会把整个数组当作一个元素, 放在Stream流中
java
import java.util.stream.Stream;
public class Demo5 {
public static void main(String[] args) {
int[] arr1 = {1, 2, 3, 4, 5, 6};
String[] arr2 = {"1", "2", "3", "4"};
Stream.of(arr2).forEach(s -> System.out.println(s));// 1 2 3 4
Stream.of(arr1).forEach(item -> System.out.println(item));//[I@19dfb72a
}
}Stream的常用方法
中间方法
| 方法名 | 说明 |
|---|---|
Stream<T> filter(Predicate predicate) | 用于对流中的数据进行过滤 |
Stream<T> limit(long maxSize) | 返回此流中的元素组成的流,截取前指定参数个数的数据 |
Stream<T> skip(long n) | 跳过指定参数个数的数据,返回由该流的剩余元素组成的流 |
static <T> Stream<T> concat(Stream a, Stream b) | 合并a和b两个流为一个流, 需尽可能保持类型一致, 如果不一样, 那么流中的类型就是它们共同的父类 |
Stream<T> distinct() | 返回由该流的不同元素根据equals()和hashCode()组成的流, 底层使用了HashSet |
Stream <R> map(Function mapper) | 转换流中的数据类型, 返回一个新流 |
提示
- 中间方法, 返回新的Stream流, 原来的流只可以使用一次, 建议使用链式编程
- 修改流中的数据不会影响原来的集合或数组中的数据
java
//distinct使用注意点
public class Demo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5, 6, 6, 5);
//去重
list.stream().distinct().forEach(val -> System.out.println(val));
ArrayList<Student> stuList = new ArrayList<>();
stuList.add(new Student("wang", 19));
stuList.add(new Student("jia", 20));
stuList.add(new Student("wang", 19));
/*
Student是一个标准的JavaBean, 并且重写了toString()
* Student{name = wang, age = 19}
Student{name = jia, age = 20}
Student{name = wang, age = 19}
这时的Student类并没有重写equals和hashCode方法, 那么默认按照地址值比较
*
* 重写之后, 结果为:
Student{name = wang, age = 19}
Student{name = jia, age = 20}
* */
stuList.stream().distinct().forEach(student -> System.out.println(student));
}
}java
public class Demo7 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("汪加年-19");
list.add("小小汪-21");
list.add("励志汪-20");
//Function接口:
// 泛型一: 当前流上元素类型, 与参数s对应,
// 泛型二: 返回的元素类型, 与返回值对应
//map方法会把所有的返回值, 作为一条新的流返回
list.stream().map(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
String[] item = s.split("-");
String age = item[1];
int resultAge = Integer.parseInt(age);
return resultAge;
}
}).forEach(val -> System.out.println(val));//19 21 20
}
}终结方法
| 方法名 | 说明 |
|---|---|
void forEach(Consumer action) | 对此流的每个元素执行操作 |
long count() | 返回此流中的元素个数 |
toArray() | 将流中的元素转换为数组 |
collect(Collector collector) | 将流中的元素收集到集合中 |
提示
toArray(), collect()方法是收集类别的方法
java
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.function.IntFunction;
public class Demo8 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5);
//打印元素个数
long count = list.stream().count();
System.out.println(count);// 5
//将流中的数据转换为Object类型数组
Object[] objects = list.stream().toArray();
System.out.println(Arrays.toString(objects));
//IntFunction
// 泛型一: 返回值类型, 对应着数组中类型
//参数value: 表示数据的长度, 而不是每一个数据
Integer[] arr = list.stream().toArray(new IntFunction<Integer[]>() {
@Override
public Integer[] apply(int value) {
System.out.println(value);// 5
return new Integer[value];
}
});
System.out.println(Arrays.toString(arr));// [1, 2, 3, 4, 5]
}
}收集方法
收集方法是终结方法的一种
概念
对数据使用Stream流的方式操作完毕后,可以把流中的数据收集到集合中
常用方法
| 方法名 | 说明 |
|---|---|
R collect(Collector collector) | 把结果收集到集合中 |
- 工具类
Collectors提供了具体的收集方式
| 方法名 | 说明 |
|---|---|
public static <T> Collector toList() | 把元素收集到List集合中 |
public static <T> Collector toSet() | 把元素收集到Set集合中 |
public static Collector toMap(Function keyMapper,Function valueMapper) | 把元素收集到Map集合中 |
收集到List和Set中
java
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class Demo9 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-男-15", "张无忌-男-15", "张三丰-男-20", "胡桃-女-19");
//收集到List集合当中, 把所有的男性收集起来
List<String> newList = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toList());
System.out.println(newList);// [张无忌-男-15, 张无忌-男-15, 张三丰-男-20]
//收集到Set集合当中, 把所有的男性收集起来
Set<String> newSet = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toSet());
//Set集合会去重
System.out.println(newSet);// [张三丰-男-20, 张无忌-男-15]
}
}收集到Map中
java
public class Demo9 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-男-15", "张三丰-男-20", "胡桃-女-19");
//toMap的第一个形参是制定键的规则; 第二个是值的规则
//key规则:
//泛型一: 流中的数据类型, 与apply方法的形参对应
//泛型二: Map集合中键的类型, 与返回值类型对应
//apply() 形参表示流中的每一个数据
// 方法体: 生成键的代码
// 返回值: 已经生成的键
//value规则:
//泛型一: 流中的数据类型, 与apply方法的形参对应
//泛型二: Map集合中值的类型, 与返回值类型对应
//注意点: 如果我们要把数据收集到Map集合中, 那么键不可以重复, 否则代码报错
Map<String, Integer> map = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(new Function<String, String>() {
@Override
public String apply(String s) {
return s.split("-")[0];
}
}, new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[2]);
}
}));
//使用lambda表达式简化
Map<String, Integer> map1 = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(s -> s.split("-")[0], s -> Integer.parseInt(s.split("-")[2])));
System.out.println(map);//{张三丰=20, 张无忌=15}
}
}危险
注意点: 如果我们要把数据收集到Map集合中, 那么键不可以重复, 否则代码报错java.lang.IllegalStateException: Duplicate key 张无忌 (attempted merging values 15 and 15)
java
//参考toMap方法中的uniqKeysMapAccumulator()方法
//在底层源码中u就代表着键, 如果键不重复, 则u为null, 如果键重复, 则u为旧的值, 最后就会跑错
if (u != null) throw duplicateKeyException(k, u, v);